This assignment aims to give you practice in:
The task is to take a small web search engine, analyse its performance and implement a new indexing subsystem for it which has better performance.
Note: the material in the lecture notes is not sufficient by itself to allow you to complete this assignment. You will probably need to refer to a decent C textbook (e.g. "The Indispensable Guide to C" by Davies) and a good data structures or file structures text (e.g. "File Structures" by Folk and Zoellick).
This assignment ...
give cs2041 ass3 Report.txt src.tgz
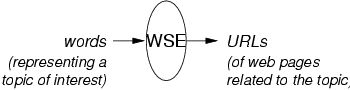
Web Search Engines (WSEs) are indispenable tools for dealing with the vast ocean of information available on the Web. Just about everyone has used Google to find web pages that deal with some topic of interest. We all know the user perspective on WSEs
We also all know that often the WSE's intpretation of "relevant" doesn't match with our own. This arises because all existing WSEs try to make sense of documents by considering each of them simply as a set of words. They do not understand the "meaning" of the documents they deal with, which is what we use to judge relevance. Google's trick for solving this problem is to rank documents according to their "authority", as measured by the number of incoming links to each document; in this way, Google tends to rank "important" documents first, which tends to correspond to what users want.
Stripped to its bare essence, a Web Search Engine is just a function that maps words to URLs:
To be more precise, a WSE can take a single word w and return the set of URLS for all documents di that contain w:
Most WSEs allow multiple words wj to be supplied and typically return all documents di that contain any of those words:
| Results(w1 w2 ... wn) |
| = { di | di contains w1 OR di contains w2 OR ... di contains wn } |
| = { di | di contains w1 } ∪ { di | di contains w2 } ∪ ... { di | di contains wn } |
Documents that contain more of the words from the query are usually judged to be "more relevant" than ones which contain only one or two of the specified words, and this is commonly used as a factor in determining "relevance" of documents.
WSEs also generally allow you specify that a particular word wj must be present in any matching document or that a word wk must not be present in any matching document. The syntax for these operations varies from WSE to WSE, but it is quite common to use + to indicate that a word is required, and - to indicate that a word must not be present.
The following examples illustrate the semantics of WSE queries:
Results(red flower) = { di | di contains "red" OR di contains "flower" }
Results(apple -fruit) = { di | di contains "apple" AND NOT di contains "fruit" }
Results(+cat dog pet) = { di | di contains "cat" AND (di contains "pet" OR di contains "dog") }
If we consider the query words individually, it is easy to express the meaning of the operators using the set operations union (∪), intersection (∩), and difference (-):
The order of operations is important; to get the correct semantics, we need to perform the union operations before we do the intersection and difference operations. The way that search.c implements the semantics is as follows:
To make this semantics work properly, if there are no OR words, then you need to start with the entire set of documents before applying the rules for AND and NOT. Since this is completely infeasible for something like a web search engine (the entire set of documents is huge), then we are going to add the requirement that at least one OR keyword is present in any query. If not, the result set will be empty.
In order to carry out queries like those above, a WSE collects and stores data about web pages. A real search engine stores an extremely large amount of such data. To answer queries efficiently, it needs to arrange this data using a search-friendly storage structure (generally called an index).
Information is gathered by a spider (or "robot") program that traverses the web and collects a list of words and links from each page that it visits. It stores the words in its index, associating them with the URL of the page. It uses the links to continue its traversal. The index itself is maintained as a collection of files organised to minimise the cost of later searching.
WSEs make various transformations on the list of words that comprise a document, to make the process of answering queries more effective:
The implementation of a real Web Search Engine requires consideration of sophisticated techniques from information retrieval, databases and artificial intelligence. We won't worry about these techniques for the purposes of this exercise. If you're interested in this, you can find more information in The Anatomy of a Large-Scale Hypertextual Web Search Engine by Lawrence Page and Sergey Brin (the Google creators).
For this exercise, we will consider a simple search engine that doesn't attempt to order the list of result documents to put the "most relevant" ones first, but does do stemming, stop-word removal, and supports the "+" and "-" operators described above.
Our Web Search Engine, Seeker, has the following system architecture:
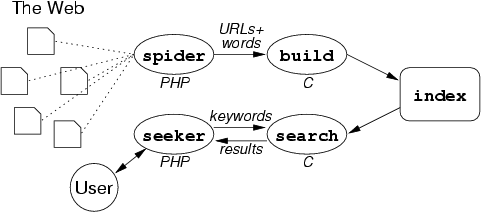
Notice that the spider is implemented in PHP, which has good facilities for interacting with Web pages and string processing. The web user interface (seeker) is also written in PHP. If a Search Engine cannot deliver its results quickly, nobody will use it, so the performance-critical parts of the system (building and searching the index) are implemented in C.
The "context" information is provided simply by stripping tags from the HTML and grabbing the first 50 words from the document. The list of words is "normalised" by stemming and removing stop words as described above. Note that we don't make any use of word frequencies in this assignment.
-c, which tells it to
create a completely new index (removing any existing index first).
It reads the spider output from its standard input.
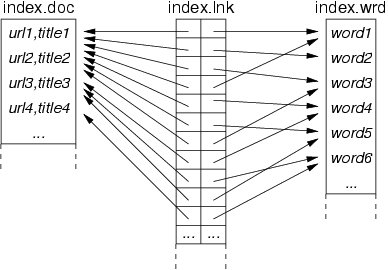
The index itself must contain at least a list of document URLs and titles,
and a table that can map a word into a set of documents.
This will typically be achieved by having multiple files, each with a
different role.
Note that you do not need to use the spider script in this assignment; you can use the spi.* files as input to build. In theory, you can also use the search command directly, but you need to be careful to do your own stemming and stopword removal and make sure you put the arguments in the correct order, so it's probably safer to do all queries via the seeker script.
Report.txt
Report.txt is available; you do not
have to follow this format exactly)
src.tgz
The source code for the Seeker system is packed as a
gzipped tar archive in the assignment directory.
You can extract it via the command:
tar xfz /home/cs2041/web/07s2/ass/3/seeker.tgz
This will unpack a collection of files into your current directory, so make sure that you're in your Assignment 3 directory before you run tar.
You'll find the following files in the directory:
The spider output files provide data that can be used by the build program to create a number of different indexes:
Note that you may not have enough disk quota (or time to wait) to build an index for spi.php file.
However, you find that the search engine software is in a rather sorry state. There's a problem with the + operator and it can't do the performance monitoring that they want it to do. Worse, however, is that it is simply way too slow and builds indexes that are far too big. They'll never be able to index the entire Web given the current state of the software.
As a new employee, you naturally get the best jobs. Your new boss tells you ... "Can you fix the problem with +, and then fix the performance monitoring and finally build a new index structure that works faster and takes less room than the current one? If you can do it all in four weeks we'll give you oodles of stock options. Get to work."
And so your task begins ...
As you complete the exercises below, you should keep notes in an HTML-format file called Report.txt. You are required to submit this file.
Complete the following exercises with the Seeker system:
Take a look at the Makefile and make sure that understand what targets are available. You should also take note of the FLAGS variables, because you will need to set these later to do debugging and profiling.
The Makefile can do a number of different tasks:
You should spend some time seeing how it does this, and what dependencies it specifies (just in case it doesn't re-compile something that you think it should in the future). And, of course, if you add more stuff to your system, you may need to modify it to include your new code files.
Warning: if you plan to use the system via the CSE CGI server, it must be compiled on a CSE workstation, to ensure that the binaries will run on the CGI server. You also need to copy the files seeker, seeker.css, search and Index.* into the CGI directory. And you must compile search on a CSE workstation to ensure that it's binary-compatible with the CGI server.
Compile the system and build an index by running make Index. You should observe the following output:
$ make Index gcc -g -Wall -c -o build.o build.c gcc -g -Wall -c -o index.o index.c gcc -g -Wall -c -o docs.o docs.c gcc -g -Wall -c -o fatal.o fatal.c gcc -g -Wall -c -o myio.o myio.c gcc -o build build.o index.o docs.o fatal.o myio.o build -c Index < spi.test R: 0/0 W: 0/0 S: 0 T: 0
You can ignore the last line for the time being ... you'll fix that in a later exercise.
You should notice that build has created three new files in the directory: Index.doc, Index.lnk, Index.wrd. These are the files that make up the index. They are binary files, so you cannot suefully look at them using cat, less or a text editor. However, you can get some idea of their contents using two other Unix commands:
The Index.doc file consists of a sequence of (URL,title) pairs, as '\0'-terminated C strings, so the strings command will give you a good idea of the file contents. Each document is represented by the offset of its URL within the file (this is called a DocID) in the code).
The Index.wrd file consists of a collection of words, as '\0'-terminated C strings, that are packed into "blocks" (fixed size sections of the file). The data content of each block is terminated by an empty string. A block may be full, or may have empty space at the end. The diagram below gives an idea of what the file looks like. Each word is represented by its offset from the start of the file (this does not have an explicit data type in the code, but could be called a WordID).
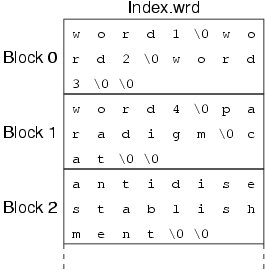
The Index.wrd created here has only one block, but you can examine its contents using either the strings command or the od command.
The Index.lnk file consists of a sequence of (DocID,WordID) pairs, one pair for each occurrence of a word in a document. (Note that the code actually stores these as (WordID,DocID) pairs.) Since it consists of binary data (pairs of file offsets), it only makes sense to examine this file using the od command. You should try to relate what you see to the diagram below.
You ought to take a look at the source code now, to work out how this index is constructed and used. Start by looking at build.c and search.c and then work your way down into the lower level modules index.c and docs.c.
This reading phase is important because it will help you with the debugging and modification exercises later on. However, don't agonise over understanding every fine detail at this stage. As long as you have an overview of how the code fits together, you're ready to proceed with the later exercises.
One important point to notice at this stage is that all input/output to the index is done via the myfread and myfwrite functions. You must adhere to this convention throughout any implementation you undertake.
Note: Before you continue, make sure that you have built the search binary by running make search.
Try to ask a query using the seeker script, e.g.
$ php seeker The Yellow Apples QUERY: The Yellow Apple EXEC: search Index yellow appl STOPWORDS: the 3 RESULTS: http://www.cse.unsw.edu.au/~cs2041/07s2/ass/3/test/index.html Index Blue Index This page is blue, but also refers to: a red page a green page a yellow page... http://www.cse.unsw.edu.au/~cs2041/07s2/ass/3/test/p1.html Red Red Apples This page is red. It talks about apples. And that's all.... http://www.cse.unsw.edu.au/~cs2041/07s2/ass/3/test/p3.html Yellow Yellow Stuff This page is yellow. It talks about bananas. And that's all.... R: 17260/68 W: 0/0 S: 7 T: 0 $ php seeker green QUERY: green EXEC: search Index green STOPWORDS: 2 RESULTS: http://www.cse.unsw.edu.au/~cs2041/07s2/ass/3/test/index.html Index Blue Index This page is blue, but also refers to: a red page a green page a yellow page... http://www.cse.unsw.edu.au/~cs2041/07s2/ass/3/test/p2.html Green Green Page This page is green. It's all about trees. It also has a link back to the index.... R: 8734/36 W: 0/0 S: 4 T: 0 $ php seeker page -green QUERY: page -green EXEC: search Index page -green STOPWORDS: 2 RESULTS: http://www.cse.unsw.edu.au/~cs2041/07s2/ass/3/test/p1.html Red Red Apples This page is red. It talks about apples. And that's all.... http://www.cse.unsw.edu.au/~cs2041/07s2/ass/3/test/p3.html Yellow Yellow Stuff This page is yellow. It talks about bananas. And that's all.... R: 17093/64 W: 0/0 S: 6 T: 0
The output contains some debugging information (in green) and some performance information (in red), and the actual results (in black). This query has given the correct results, since every web page in our small example contains either the word "page" or the word "red" (or both).
Note that seeker is essentially doing some cleaning of the keywords and then invoking the search program using the index with basename Index. Compare the seeker arguments to the search arguments in the first example to see some stemming ("apples">"appl") and stopword removal ("the").
Try a few more queries and see if you notice any problems. In particular, try a query like php seeker red +page. On some systems, this may give no results. On others, it might crash. Your task is to work out why, and then fix the problem.
Hints:
There are no bugs in seeker. Any bugs must therefore be somewhere in the functions used in the search program that seeker invokes.
Notice that seeker tells you how it's invoking the search program (on the line beginning with EXEC). When you want to debug search, you should run it with the arguments shown there.
You might find the dsTest program useful in helping you to isolate the problem. You can build this using the make dsTest command. Read the source code to find out how to use it.
You should describe in the Report.txt file how you performed the debugging, including a description of the kinds of queries you used, and how they provided evidence for your debugging hypotheses.
Note that there is no point considering the performance of a program that does not work correctly, so you should not proceed onto the following exercises until you are certain that the bug has been repaired.
You would have noticed above that output from the build and search commands ended with a line that looks like:
R: 0/0 W: 0/0 S: 0 T: 0
This is an incomplete attempt to produce input/output statistics for the programs. This line is supposed to contain the following information:
R: nrbytes/nreads W: nwbytes/nwrites S: nseeks T: ntells
where
nrbytes = total number of bytes read from all files nreads = total number of fread operations on all files nwbytes = total number of bytes written to all files nwrites = total number of fwrite operations on all files nseeks = total number of fseek operations on all files ntells = total number of ftell operations on all files
If you don't know what some of these operations do, take a look at a decent C textbook or the on-line C manual.
These numbers tell us how much input/output the program is doing. We'll use this information as a basis for determining whether our new indexing scheme (file structure) is giving better performance. Clearly, our goal is to give exactly the same (correct) answers to queries, but to do less input/output so that users don't have to wait as long to get the answers.
This functionality is supposed to be provided by myio.c library. It has a function (startMyIO) to tell the system to start collecting I/O statistics, and another function (showMyIO) to display the collected statistics. In between, all I/O should be done via the functions myfread, myfwrite, myfseek and myftell, which are simply wrappers around the real C functions that do the work.
If you take a look at the functions in myio.c, it's clear that someone has forgotten to add the code to collect the statistics. Your task is to modify the wrapper functions so that they collect the correct statistics as outlined above.
Once you have done this correctly, you should observe something like the following output from the build program (although you do not need to build indexes for the very large data files):
| Data File | I/O costs for building index from this data file | Timing Data |
|---|---|---|
| spi.test | R: 319488/54 W: 123707/57 S: 86 T: 4 |
0.00u 0.00s |
| spi.jas | R: 21061632/3321 W: 6164276/2657 S: 5167 T: 21 |
0.08u 0.02s |
| spi.lecs | R: 126083072/17655 W: 18750912/15135 S: 27112 T: 451 |
0.82 0.09s |
| spi.perl | R: 1133838336/145357 W: 57549685/75187 S: 148122 T: 321 |
11.2u 0.63s |
| spi.php | R: 5865078784/729106 W: 112651951/399691 S: 750033 T: 7048 |
57.3u 3.4s |
In the above results, the counts for number of bytes read in the last
two examples have suffered from integer overflow and so are reported
as ???. The index, however, was built successfully.
While you might not get exactly the same numbers as above, you ought to get numbers that are "close to" these. You'll get different numbers if you use a different, but equally valid, bug-fix to that used in my solution.
Note that you must count the actual bytes read/written, not the requested bytes read/written; go and check the definition of fread and fwrite if you don't understand the difference.
In your Report.txt file, you should comment on these figures, relating the I/O costs to the number of documents and words in each of the data files. Draw some conclusions on the implications with respect to scalability.
You should also devise a set of queries to exercise the search program in various ways. Document these queries in Report.txt, and show the I/O statistics when they are run against the index from the spi.lecs data.
The above I/O statistics give a good idea of how much data is being transferred around by the build and search programs. However, they don't consider what's happening inside these programs. In order to investigate this, you need to compile the programs with profiling enabled.
To do this, first clean up the existing programs, then set the -pg flag for the compiler and loader, and re-make the build and search programs.
Run the build program on the spi.lecs data file and construct a new index for it. Use the following command, so that you get an overview of the time cost for the program:
time build -c Index < spi.lecs
After you've done that, use the gprof command to check which functions are consuming most of the execution time.
If one or two functions stand out as being expensive, try to determine why they are consuming so much time. If you can't work this out simply by inspecting them, then try partitioning them into sub-functions and seeing which sub-function is contributing most of the cost. Once you have a reasonable understanding of the causes of any inefficiency, suggest how it might be improved.
One important point to note is that the execution time might be a relatively small component of the overall cost. Compare the overall time from the build command to the time measured in gprof to determine whether this is the case. What might the program be doing if it's not excuting lines-of-code?
In your Report.txt file, put a discussion of your discoveries. Please include the flat profile from a typical gprof output and the output from time as a basis for your discussion.
Now use the set of queries that you developed in the previous exercise and examine the performance of the search program (you can still obtain a profile if you invoke search via the seeker script). Perform the same kind of analysis as you did for the build program and report your findings in Report.txt.
Your next task is to propose a new structure for the index that will give improved input/output performance over the original version (if it reduces disk space usage as well, that's even better). This is the major progrmaming task for this assignment and will require you to completely replace the contents of the functions in the index.c module. Note that you should not change the interface to index.c, just how it does its job. To get started, you should first copy the original index.c code to a safe place (e.g. index0.c), just in case you ever want to reconstruct the original versions of the programs.
In designing your new index structure, you can get ideas from anywhere you like (except from other students in COMP2041), or can try to invent a new structure yourself. Some places to look include database textbooks (the chapters on indexing) or the "File Structures" textbook which was once used in COMP2011. You might also get some ideas from the lecture notes for the Database Systems Implementation course.
Some requirements to keep in mind for the new index
build -c Index < spi.test build Index < spi.jas build Index < spi.lecsand this should have the same effect as
cat spi.test spi.jas spi.lecs | build -c Index
You are completely free to choose any algorithm and associated file structures for the new index structure, as long as they satisfy the above constraints. In particular, you do not have to retain the existing three-file structure; you could use a single file or as many files as you like, as long as they don't end up consuming an inordinate amount of space.
One simple approach would be to leave the current file structure intact, but add some auxiliary files that improved the searching performance (this would consume more disk space, but if it improves the searching performance and the extra disk space is not excessive, that is ok). Other approaches might require completely replacing the existing file structure.
Whatever you do, the ultimate goal is to achieve better i/o performance than the existing method. To encourage excellence, I'll give a prize to the person who achieves the smallest/fastest general index structure. Send me email if you think you've got a particularly good solution.
In Report.txt, you should document your design considerations for the new indexng scheme and describe how you tested it to assure yourself that it was working.
You are allowed to introduce extra .c and .h files, but you must include them correctly in the Makefile.
Once you have completed and tested your new index scheme, repeat the I/O analysis that you did in Exercise 4 for the original indexing scheme and compare the differences. Put your findings in Report.txt.
Note that even if your new indexing scheme is slower than the original one, as long as it's correct and you have done a good job of analysing its performance, you can still achieve some marks for the last three exercises in this assignment.
Repeat the profile analysis from Exercise 5 for your new indexing scheme, and compare it to the results for the original scheme. Put your findings in Report.txt.
The aim of this assignment is for you to (a) explore the system that we have provided, (b) think about the reasons for the problems with this system, and then (c) devise (or find elsewhere) a better algorithm to implement. We are expecting you to use your own initiative in debugging the system, doing the performance analysis, and, coming up with a better indexing algorithm. The only restriction on your initiative is that you can't copy code from other students in the class.
You may, however, grab indexing code from anywhere on the Web, provided that you modify it so that it fits into our existing framework. In particular, it has to produce the same kind of input/output analysis as the current system does (e.g. you must change all uses of fread, etc. in the original code to use myfread, etc.). Naturally, if you use someone else's code as a base, you must attribute it to them (e.g. by leaving authorship and copyright notices intact). Something to think about before embarking on the use of code from elsewhere: it's sometimes more difficult to adapt code to fit your system than to write it from scratch.
You must submit all of the C code required for your system, along with a Makefile to compile it properly, and the Report.txt file that contains your observations and discussions from this assignment.
The Makefile, along with all of your C code must be packed into a gzipped tar archive. When the archive is unpacked, it must place the Makefile into the current directory, and the C code either in the same directory or in subdirectories. Your C code must include your versions of the files build.c and search.c and your Makefile must produce (as a minimum) two executable programs called build and search.
If, for example, you stick to exactly the same set of files as in the supplied code, then you would create your archive by executing the following command in your Assignment 3 directory:
tar cfz src.tgz Makefile *.c *.h
On the other hand, if you used libraries that lived in subdirectories called indexlib and wombat as part of your solution, then you would create your archive by executing the following command in your Assignment 3 directory:
tar cfz src.tgz Makefile *.c *.h indexlib/ wombat/The critical point about your src.tgz archive is that when we unpack it for testing, it will place the Makefile in the current directory and unpack all of the other C code such that when the Makefile is invoked, it will create two binaries called build and search. If your archive is not set up like this, you will be penalised via an admin penalty of -2 marks.
It is thus imperative that you check the functioning of your archive by something like the following: create a new empty directory, copy src.tgz into this new directory, run the following commands from within the new directory:
tar xfz src.tgz make
If this creates build and search in the new directory, then your archive is acceptable.
Your submitted programs will be auto-tested as follows:
The auto-testing results will be supplied to the markers to consider when they are examing the code for the assignment.
The marks below add up to more than then 12 marks for this assignment. The total will be scaled into a mark out of 12. You can achieve partial marks for the components. It is possible to achieve a pass