GSoC 2019 Report Update: Incorporating the memory-hard Argon2 hashing scheme into NetBSD
Introduction
As a memory hard hashing scheme, Argon2 attempts to maximize utilization over multiple compute units, providing a defense against both Time Memory Trade-off (TMTO) and side-channel attacks. In our first post, we introduced our GSOC project's phase 1 to integrate the Argon2 reference implementation into NetBSD. Having successfully completed phase 1, here we briefly discuss parameter tuning as it relates to password management and performance.
Parameter Tuning
Both the reference paper [1] and the forthcoming RFC [2] provide recommendations on how to determine appropriate parameter values. While there are no hard-and-fast rules, the general idea is to maximize resource utilization while keeping performance, measured in execution run-time, within a tolerable bound. We summarize this process as follows
- Determine the Argon2 variant to use
- Determine the appropriate salt length
- Determine the appropriate tag length
- Determine the acceptable time cost
- Determine the maximum amount of memory to utilize
- Determine the appropriate degree of parallelism
Step 1
All three Argon2 variants are available in NetBSD. First,
argon2i is a slower variant using data-independent memory access suitable for password hashing and password-based key derivation. Second,
argon2d is a faster variant using data-dependent memory access, but is only suitable for application with no threats from side-channel attacks. Lastly,
argon2id runs argon2i on the first half of memory passes and argon2d for the remaining passes. If you are unsure of which variant to use, it is recommended that you use
argon2id.[1][2]
Step 2-3
Our current implementation uses a constant 32-byte hash length (defined in crypt-argon2.c) and a 16-byte salt length (defined in pw_gensalt.c). Both of these values are on the high-end of the recommendations.
Steps 4-6
We paramaterize Argon2 on the remaining three variables: time (t), memory (m), and parallelism (p). Time
t is defined as the amount of required computation and is specified as the number of iterations. Memory
m is defined as the amount of memory utilized, specified in Kilobytes (KB). Parallelism
p defines the number of independent threads. Taken together, these three parameters form the
knobs with which Argon2 may be tuned.
Recommended Default Parameters
For default values, [2] recommends both argon2id and argon2d be used with a time t cost of 1 and memory m set to the maximum available memory. For argon2i, it is recommended to use a time t cost of 3 for all reasonable memory sizes (reasonable is not well-defined). Parallelism p is a factor of workload partitioning and is typically recommended to use twice the number of cores dedicated to hashing.
Evaluation and Results
Given the above recommendations, we evaluate Argon2 based on execution run-time. Targeting password hashing, we use an execution time cost of 500ms to 1sec. This is slightly higher than common recommendations, but is largely a factor of user tolerance. Our test machine has a 4-core i5-2500 CPU @ 3.30GHz running NetBSD 8. To evaluate the run-time performance of Argon2 on your system, you may use either the argon2(1) or libargon2. Header argon2.h provides sufficient documentation, as well as the PHC git repo at [4]. For those wanting to use argon2(1), an example of using argon2(1) is below
m2# echo -n 'password'|argon2 somesalt -id -p 2 -t 1 -m 19
Type: Argon2id
Iterations: 1
Memory: 524288 KiB
Parallelism: 2
Hash: 7b9618bf35b02c00cfef32cb4455206dc400b140116710a6c02732e068021609
Encoded: $argon2id$v=19$m=524288,t=1,p=2$c29tZXNhbHQ$e5YYvzWwLADP7zLLRFUgbcQAsUARZxCmwCcy4GgCFgk
0.950 seconds
Verification ok
In order to establish a performance baseline, we first evaluate the run-time of all three variants using the recommended default parameters without parallelism. Our objective is to maximize memory m while constraining the execution cost between 500ms to 1sec. While we graph all three variants for comparison, our target is variant argon2id. We loop over Argon2 with monotonically increasing values of m for all three variants. Graphing our results below, we determine the maximum memory m value within our bound is 219. However, to follow common suggestions [3], we chose 220 (1048576 Bytes) with the assumption that increased parallelism will bring the execution time cost down within acceptable limits.
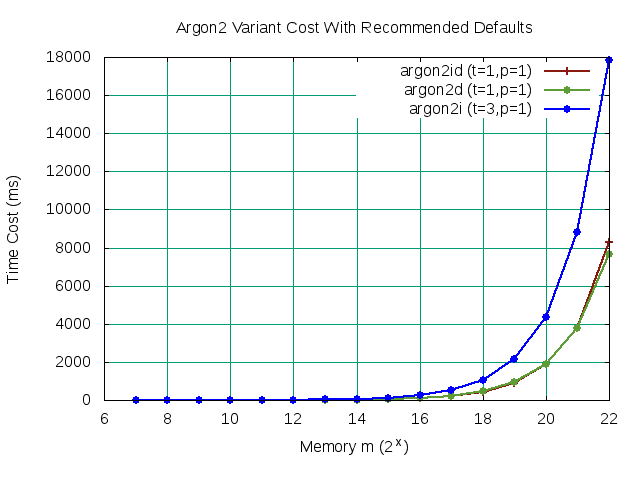 Figure 1
Figure 1
Having established our performance baseline to obtain a best guess for our memory
m value, we can turn our attention to parallelism. As touched upon earlier, common suggestions for parallelism
p is twice the dedicated core count. Threads in Argon2 form computational
lanes which allow work on the memory matrix to be partitioned into independent
slices. As such, intuition tells us that by increasing parallelism we should see a decrease in our overall run-time until we are computationally bound. In the graph below, we see the affects of increasing parallelism
p over our selected
t and
m values.
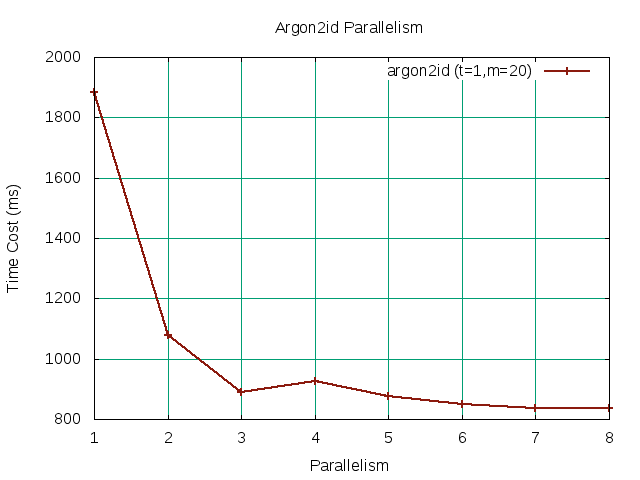 Figure 2 Figure 2 |
Our baseline memory
m value initially exceed our desired upper bound of 1sec without parallelism. Fortunately, we found that increasing the thread count sufficiently parallelizes the work until it starts to settle around
p=8. To see if we can further increase our baseline memory
m value, we can look at following the graph for argon2id with
t=1,
p=8. We note that our initial baseline value of
m=20 is the maximum
m value falling within our bound.
 Figure 3 Figure 3 |
Having all three parameters, we can validate the run-time execution easily using argon2(1) to confirm performance is within our defined bounds. Once you are satisfied, you may use passwd.conf(5) to apply the parameters globally or on a per-user basis. Our first post includes an example of adding the appropriate stanza to passwd.conf(5).
m2# echo -n 'password'|argon2 somesalt -id -m 20 -p 8 -t 1
Type: Argon2id
Iterations: 1
Memory: 524288 KiB
Parallelism: 8
Hash: c62dbebec4a2da3a37dcfa2d82bd2f55541fce80992cd2c1cb887910e859589f
Encoded: $argon2id$v=19$m=524288,t=1,p=8$c29tZXNhbHQ$xi2+vsSi2jo33Potgr0vVVQfzoCZLNLBy4h5EOhZWJ8
0.858 seconds
Verification ok
Summary
Argon2 is well-known for its high resource requirements. Fortunately, we are able to tune Argon2 so that we can achieve reasonable performance on NetBSD. In this post, we consider an approach to selecting appropriate parameter values for tuning Argon2 for password hashing. There are no hard-and-fast rules. We have found that it is easiest to start with a baseline value of memory m, then tweaking the values of parallelism p in order to achieve the desired performance.
Remaining Tasks
For the third and final portion of Google Summer of Code, we will focus on clean-up, documentation, and finalizing all imported code and build scripts. If you have any questions and/or comments, please let us know.
References
[1] https://github.com/P-H-C/phc-winner-argon2/blob/master/argon2-specs.pdf
[2] https://tools.ietf.org/html/draft-irtf-cfrg-argon2-04#section-4
[3] https://argon2-cffi.readthedocs.io/en/stable/parameters.html
[4] https://github.com/P-H-C/phc-winner-argon2